이번에 새로 알았거나, 알고는 있었지만 정작 실전에서는 몇번 써본 적 없는 구간합과 관련된 몇가지 테크닉에 대해 다뤄보려 한다.
슬라이딩 윈도우 & 두 포인터
양수가 들어있는 배열에서 구간합이 특정 값인 개수를 구할 때 자주 사용하는 알고리즘이다.
두 포인터는 시작점과 끝 점을 가리키는 두개의 포인터가 상황에 따라 움직임에 따라 구간의 길이가 유동적으로 바뀌고,
슬라이딩 윈도우는 시작점과 끝점 사이의 간격을 지정한 후, 배열 내에서 한칸씩 전진하며 마치 창문이 미끄러지듯이 작동한다는 점이 다르다.
하지만 두 알고리즘 모두 '해당 알고리즘만' 사용하는 문제는 별로 없다. 사용 시 핵심은 시간복잡도를 줄이는 것이기 때문이다.
두 알고리즘 모두 보통 O(n^2)만큼의 시간이 걸리는 작업을 O(n)만큼만 걸리도록 하기 위해서 사용한다.
대표적인 예시를 들자면 위에서 언급한 구간합 개수 찾기를 들 수 있다.
비효율적인 방법으로는 이중 for문으로 i와 j를 매번 정해가며 조건을 만족하는 구간의 개수를 찾는 것 등이 있다.
하지만, 해당 배열 내에서의 합이 '단조성'을 만족시킨다면 이 작업의 시간복잡도를 선형으로 줄일 수 있다.
'단조성' 이란 단순히 말해서 '역행'할 필요가 없는 것을 의미한다.
원소의 값이 모두 양수인 배열에서는 구간의 길이를 늘리면 반드시 합이 증가한다는 '단조성'이 존재한다.
구간의 길이를 늘렸을 경우, 즉 현재보다 총합이 작을 때를 고려하지 않아도 된다는 뜻이다.
우리가 앞서 이중 for문의 방법이 비효율적이라 칭했던 이유 또한 위와 같은 불필요한 작업을 하고 있기 때문이다.
현재 구간의 합이 목표값 보다 작으면, 반드시 끝값의 인덱스를 늘리고 크면 시작점을 증가시키며 결국 되돌아가는 시행 없이 순조롭게 배열의 끝에 도달하게 된다.
결국 시간복잡도는 두개의 포인터가 배열의 끝에 도달하는 만큼의 시간이므로 O(n)이 된다.
비교적 쉬운 개념이지만, 실제 상황에서 이러한 '단조성'을 찾는 것은 시간복잡도를 줄이는데에 매우 중요하다.
dp 점화식이 아래와 같다고 해보자.
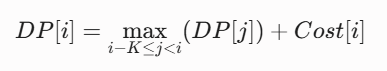
이때, 비효율적으로 구현할 경우에는 길이 K인 구간에 대해서 매번 최댓값을 찾아주어야 하기에 O(K)만큼의 비용이 발생한다.
하지만, 구간 길이가 K인 윈도우를 매번 이동시키며 최댓값을 O(1) 만에 찾아준다면, 전체 점화식의 시간복잡도가
O(NK)에서 O(N)으로 줄어들 것이다.
이 경우에는 슬라이딩 윈도우의 성질을 유지하되, 덱이라는 자료구조를 이용하여 최대값, 또는 최솟값을 유지한다.
이때 덱은 내부에서 인덱스 값이 단조성을 만족하여 '단조 큐'(monotonic queue)라고도 부른다.
(덱을 이용한 최댓값&최솟값 트릭)
어떤 원리로 작동하는지 알아보자. 최댓값을 찾는 경우를 예시로 들겠다.
이 트릭에서는 몇가지 규칙으로 인해 덱의 단조성이 보장된다.
1. 덱 내에 집어넣는 값은 배열의 실제 값이 아니라 인덱스 번호이다.
2. 새로 들어온 값은 덱의 back 쪽에 집어넣는다.
3. 새로 들어온 값 보다 작은 값들은 back 에서 부터 pop 해간다.
천천히 생각해보자. 구간을 오른쪽으로 한칸 이동시켰을 때 새로 들어오는 값의 인덱스를 i라고 해보자.
i는 가장 최근에 들어온 값이기 때문에, 덱의 가장 뒤쪽에 push 된다.
이때 back 쪽에 위치한 인덱스 중에서 arr[i]보다 작은 값을 가리키는 인덱스는 모두 pop_back() 해준다.
새로이 윈도우에 들어온 i에 비해, 이전 값들은 '더 오래되었고', '값이 작아서' 최댓값이 될 확률이 전혀 없기 때문이다.
또한, deque의 front에 있는 값, 즉 최댓값을 가리키는 인덱스가 구간의 범위를 벗어난 경우, pop_front를 해준다.
이때, 해당 덱 내에서는 단조성이 만족되기 때문에, 덱의 front를 제외하고는 범위를 벗어날 가능성이 전혀 없는 것이다.
이렇게 되면, 구간이 변함에 따라 최댓값을 구해내는 평균 성능이 O(1)에 가까워진다.
(새로 들어온 값이 매우 커서 뒤의 값을 지우는데에 O(n)의 시간이 걸릴 수도 있지만, 이렇게 되면 이후의 작업에서는 반드시 상수시간이 보장되기 때문에 평균적인 성능은 O(1)이된다.)
구현코드
deque<int> dq;
vector<int> Max;
for (int i = 0; i < arr.size(); ++i) {
if (!dq.empty() && dq.front() <= i - k) {
dq.pop_front();
}
while (!dq.empty() && arr[dq.back()] <= arr[i]) {
dq.pop_back();
}
dq.push_back(i);
if (i >= k - 1) {
Max.push_back(arr[dq.front()]);
}
}
원리와 구현 방법을 공부했으니 실전에서 사용할 수 있기를 바란다.
+
그리고 이전에 DOJ 에서 Array & Counting 2 를 풀 때 사용했던 테크닉에 대해서 다시 정리해보려 한다.
누적합 + Hashmap
음수와 양수인 값이 모두 존재하는 배열에서 구간합이 K인 구간의 개수를 구할 때 사용하는 테크닉이다.
값에 음수가 포함되어있어, 구간 길이가 길어짐에 따라 구간합이 커지는 단조성이 만족되지 않는다.
때문에, 이 경우에는 슬라이딩 윈도우나 두 포인터 대신 누적합과 누적합 정보를 기억해놓는 해시맵을 이용하여 시간복잡도를 줄일 수 있다.
구체적인 원리는 코드와 함께 설명하겠다.
int k = 10, cnt = 0; //k = 찾고자 하는 누적합 값, cnt = 횟수
map<int, int> sum_map;
sum_map[0] = 1;
for(int i = 1; i <= n; i++) {
cnt += sum_map[sum[i]-k];
sum_map[sum[i]]++;
}
cout << cnt;
만약 구간합이 K인 구간의 개수를 구하고 싶다고 해보자. 구간이 (i, j)로 표현된다면 (i < j)
sum[j] = K + sum[i] 일 것이다.
때문에, 현재 검사하는 위치가 j라면
sum[i] = sum[j]-K
을 만족시키는 i의 개수를 찾아야 할 것이다.
이는 이전까지 등장한 특정 누적합 값의 횟수를 해시맵으로 저장해놓는 방법으로 해결할 수 있다.
그리고, 현재값을 기준으로 또 다시 횟수를 업데이트하여 이후에 다시 이용한다.
누적합이 0인 값은 원소를 하나도 더하지 않았을 때 1가지가 이미 존재하므로 초기값을 1로 두는 것 또한 잊지 말자.
'알고리즘' 카테고리의 다른 글
| JUNGOL #4727 두 개의 팀 c++ (0) | 2026.06.11 |
|---|---|
| JUNGOL #5652 주유소 && #2574 사회망 서비스(복습) (1) | 2026.06.10 |
| JUNGOL #6247 최소리프노드 c++ (0) | 2026.06.09 |
| JUNGOL 백열등 2 (0) | 2026.06.08 |
| DOJ Array and Counting 2 c++ (0) | 2026.06.07 |